![[칼럼] 취약점 드러낸 IT 재해복구 진단](https://www.mantech.co.kr/wp-content/uploads/2018/12/재해복구진단.png)
[칼럼] 취약점 드러낸 IT 재해복구 진단
<1부, 이 또한 지나가리>
2001년 9월 11일, 이슬람 극단주의 세력의 동시다발적인 항공기 납치와 자폭 테러로 인해 미국 뉴욕 맨해튼의 세계무역센터와 워싱턴의 펜타곤이 공격받는 최악의 테러 사건이 발생한지 17년이 지났다. 이 사건 이후로 국내 주요 기관과 기업들은 IT 재해복구에 큰 관심을 보이기 시작했고 본격적으로 재해복구 관련 시장이 열리기 시작했다.
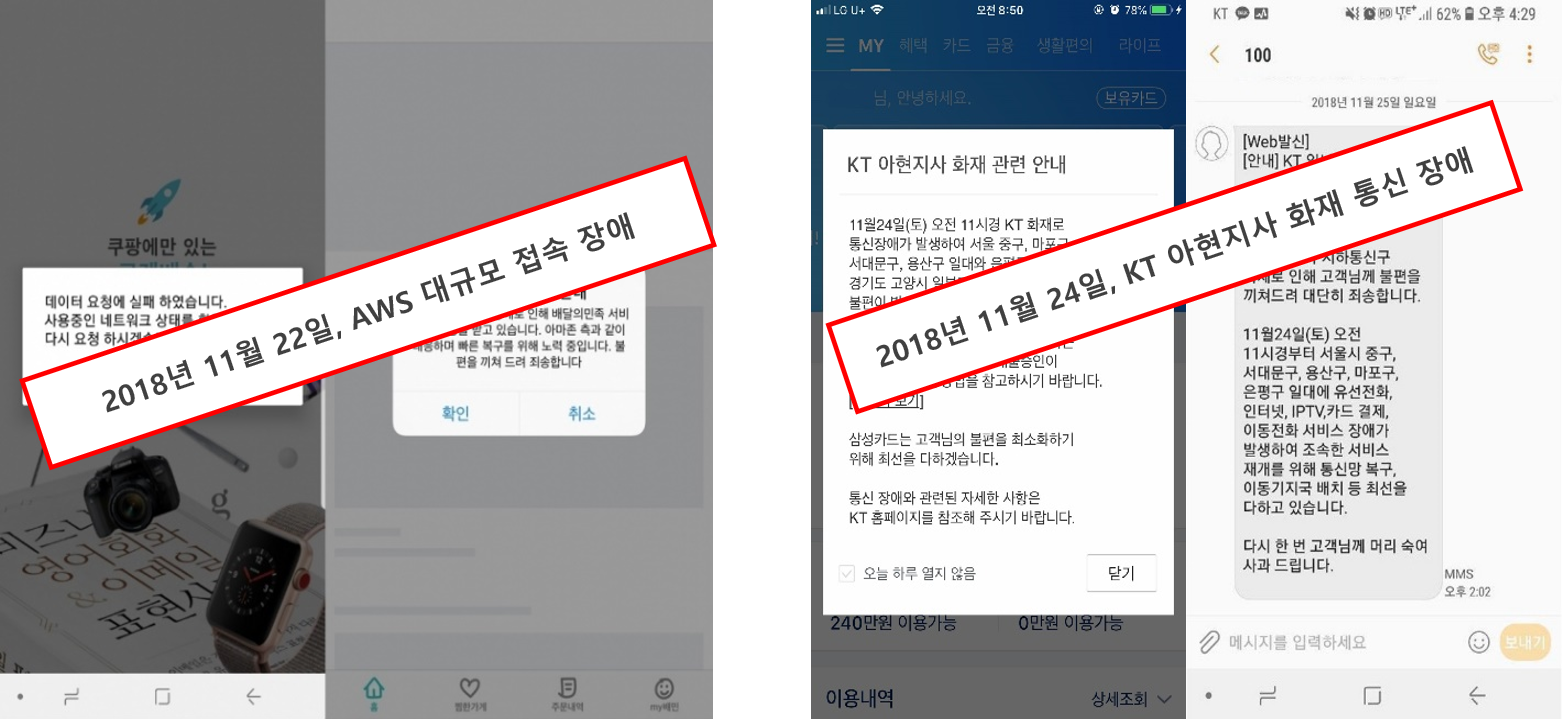
그렇다면 국내 주요 금융, 통신, 방송, 제조, 공공 등은 IT 인프라의 재해 발생 시 원활한 복구가 가능한 체계를 갖추었는가? 최근 11월 22일 발생한 AWS 서울리전의 DNS 장애와 11월 24일 발생된 KT 아현 국사의 화재 사건을 통해서 재해복구가 다시금 떠오르게 되었다. 하지만 늘 반복되는 일상이었던 것처럼 몇 개월 뒤에 다시금 수면 아래로 가라앉지 않을까 하는 우려가 있다.
과거 2011년 농협 해킹 사건, 2014년 SDS 과천 데이터 센터 화재 사건 때에도 재해복구의 중요성이 수면 위로 떠올랐다. 하지만 몇 개월 뒤 이슈는 잊혀 갔고 또 발생되겠냐 라는 인식과 함께 10년이 지나도 가동될 가능성이 없을 것만 같은 재해복구는 투자 대상에서 늘 뒷전으로 밀려나기를 반복해 왔다.
일반적으로 IT 인프라에서 재해복구가 언급되는 순간 대규모의 투자와 데이터 센터를 하나 더 구축해야 하는 부담감이 먼저 떠오른다. 또한 이렇게 구축된 데이터 센터를 하나 더 관리해야 하는 운영의 부담감 또한 만만치 않다.
기업과 기관의 입장에서도 당장 투자해야 할 클라우드, 인공지능, 머신 러닝, 블록체인 등 차세대 기술의 예산 확보도 어려운 마당에 보험성이라 할 수 있는 재해복구 관련 투자는 예산 편성에 넣기에 부담스러운 항목이 아닐 수 없다. 그냥 이 또한 지나가리라는 심정으로 재해가 발생되지 않을 거라고 위안을 삼으며 투자 항목에서 제외시키는 것이 늘 반복되어 왔다.
하지만 이것 하나는 인식해야 한다. IT의 신기술에 투자하지 않는다고 기업과 기관이 트렌드에 뒤처져 큰 손실을 입거나 역사 속으로 사라지진 않는다. 반면, 재해로 인한 중요한 서비스의 중단과 데이터의 소실은 기업을 한순간 파멸의 길로 이끌 수 있다.
11월 22일 발생된 AWS 서울 리전의 장애로 약 84분간 배달의 민족, 쿠팡, 여기 어때 등 국내 주요 사이트 여러 곳이 정상 작동되지 못한 반면 멀티리전, 이중화 및 백업, 장애 모의 훈련의 시나리오를 준비했던 기업들은 거의 피해가 없었다. 피해를 입었던 사이트의 대부분은 백업과 재해복구가 비용절감이라는 명제에 위배된다고 여겨 이를 소홀히 했기 때문이라 볼 수 있다.
또한, 11월 24일 발생한 KT 아현 국사 화재로 유무선 통신이 마비되면서 중구·용산구·서대문구·마포구 일대에서 최악의 통신 장애가 발생했다. KT 망을 이용하는 카드 결제 단말기와 포스가 먹통이 되면서 자영업자들이 영업에 차질을 빚었으며, 카드 결제 및 ATM 이용이 제한되면서 시민들은 큰 불편을 겪었다. 뿐만 아니라 청와대의 전시 지휘소인 남태령 벙커의 군 통신망 회선 수십 개가 마비되었다가 43시간 만에 복구된 것으로 확인되었다. 사상 초유의 통신 마비 사태를 부른 KT 통신국 화재 원인은 여전히 밝혀지지 않고 있으며 아직까지도 완전히 복구되지 않은 상태이다.
재해복구를 부담 큰 투자라고 여기지 말고 현재 단계에서 실천하기 쉬운 것부터 시작하자. 현재 대부분의 기업들은 데이터 백업을 받고 있을 것이다. 365일 백업은 받고 있지만 평상시 백업본으로 제대로 복구가 되는지에 대한 점검이나 모의 훈련은 거의 시행하지 않고 있다. 백업본을 활용한 복구 모의훈련부터 일상화 해보길 적극 권고 드린다. 통상적으로 백업 데이터의 복구 실패율이 약 40%에 이르고 이로 인한 비즈니스 복구 실패율은 무려 70%에 육박하기 때문이다. 백업과 재해복구 솔루션의 궁극적인 목적이 복구에 있으므로 이에 대한 훈련과 복구가능성에 대한 점검을 소홀히 해서는 안된다.
모든 일상이 디지털화된 현재, 재해복구를 이 또한 지나가리라고 가슴 졸이며 건너뛰기에는 너무나도 소중한 데이터와 서비스의 모든 것이 클라우드와 데이터센터에 저장되어 있다.
<2부, 100% 복구 가능한 재해복구 시스템을 어떻게 갖출 것인가>
IT 인프라 운영자의 가장 핵심 업무 중의 하나는 네트워크, 서버, 스토리지, 응용프로그램 등을 포함한 IT 자원들이 아무런 문제없이 연속적인 서비스가 가능하도록 제반 여건과 체계를 갖추는 것이다. 하지만 제아무리 완벽한 시스템이라 할지라도 장애나 재해로 인한 서비스 중단의 위험요소는 늘 존재하며, 이는 운영자에게 있어 큰 스트레스로 작용한다. 따라서 장애나 재해로 인한 전산 서비스 중단은 발생 가능성을 열어 둘 수밖에 없고 이러한 최악의 상황 발생 시 완벽에 가까운 복구를 어떻게 할 것인가에 대해서 체계적인 프로세스를 정립해야만 한다.
복구를 위해 가장 먼저 고려해야 할 사항
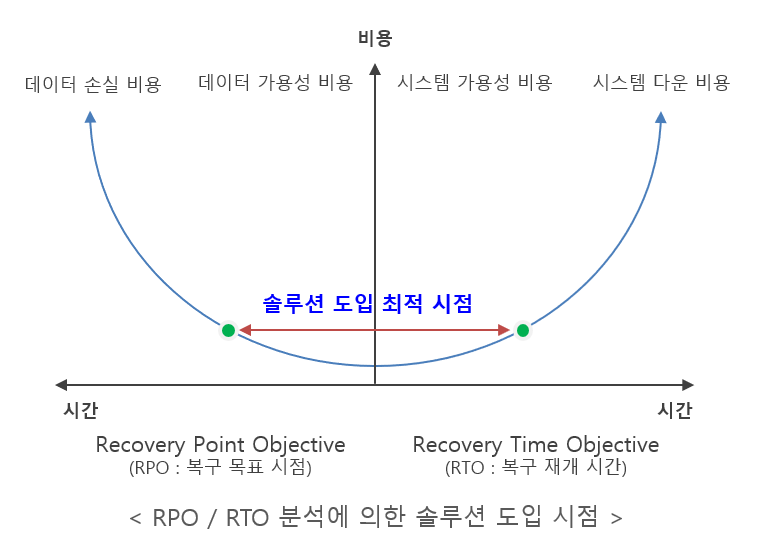
먼저 각 업무별로 서비스 중단을 감내할 수 있는 시간을 정의해야 하는데, 이를 RTO(Recovery Time Objective)라고 칭한다. RTO가 규정으로 정해져 있는 기관들도 있지만 그렇지 못한 기업이나 기관들은 업무 중단에 따른 손실 비용과 기업의 연속성에 어떠한 영향을 끼칠지 감안하여 이를 설정해야 한다. 각 업무별 RTO에 대한 정의가 끝나면 이와 연관된 IT 자원들이 어떻게 구성되어 있으며, 이에 대한 각 요소들의 복구 절차와 RTO에 대한 정의가 필요하다.
RTO에 대한 정의가 완료되면, 복구 시점에 대해 정의해야 한다. 이를 RPO(Recovery Point Objective)라고 한다. 복구할 데이터의 중요도에 따라 RPO는 바로 재해 직전, 1시간, 3시간, 하루, 일주일, 한 달 등 다양한 시점이 나올 수 있다. RPO=0이 가장 이상적이겠지만 문제는 비용이다. 이는 솔루션에 대한 비용뿐만 아니라 운영센터와 재해복구센터 간 데이터를 손실 없이 실시간으로 동기화하기 위해 필요한 큰 네트워크 대역폭으로 인해 발생하는 과도한 회선 비용, 네트워크 장비 등에 대한 유지비용을 불러오기 때문이다.
따라서 업무와 데이터의 중요도에 따라 RPO를 정의하여야 할 것이다. 예를 들어 금융업무라고 해도 모두 수시간 내의 RTO와 0에 가까운 RPO를 설정할 필요가 없다. 계정계와 같은 단 하나의 트랜잭션이 1조 원의 가치를 증빙할 수 있는 업무나 데이터의 경우에는 완전 무중단과 무손실의 복구 체계를 갖추어야 하겠지만 사내 업무 공유를 위한 포털의 경우는 좀 더 느슨한 RTO와 RPO를 설정할 수도 있을 것이다. 이러한 RTO와 RPO의 설정이 마무리되면 이를 충족할 수 있는 백업 및 복구 솔루션은 자연스럽게 매칭이 된다.
복구 순서, 변경관리 그리고 복구 테스트의 중요성
2010년대 초반, 금융권과 언론사에서 해킹으로 인한 재해가 발생하였는데 재해복구 센터가 작동되지 않은 사건들이 있었다. 또한, 외국계 모 금융기관은 재해복구 센터를 가동하는데 성공은 했지만 금감원의 권고사항인 RTO 3시간 이내를 준수하지 못했었다. 이로 인해 재해복구 무용론이 대두되었는데, 그 이유들을 살펴보면 100% 재해복구 센터가 제 기능을 발휘하지 못하였기 때문이다. (20여 년간 이 분야에 종사하면서 부끄럽게도 재해복구 센터가 아주 매끄럽게 작동되는 경우는 거의 못 본 것 같다.) 제 기능을 발휘하지 못한 원인들은 많겠지만 대표적인 원인들을 꼽자면 세 가지로 축약된다.
첫째, 복구 순서를 제대로 인지하지 못한다. 좀 황당하게 들릴 수도 있겠지만 엄연한 사실이다. 가상화와 클라우드로 인해 IT 자원이 무한에 가깝게 수 분내로 생성이 가능한 세상이다. 관리자나 운영자가 인지하기도 전에 이러한 자원들이 마구 생성된다. 또한 시간과 장소에 제한없이 접속 가능한 모바일로 인해 애플리케이션의 라이프사이클이 단축되면서 거의 매일같이 버전이 바뀌고 있다. 그에 비해 복구 순서가 정의된 복구 절차서는 이미 수년 전의 상태에서 업데이트되지 못한 채로 캐비닛에 보관되어 있다. 지난 십 수 년간 거의 매일같이 변화를 겪어온 IT의 인프라의 장애나 재해를 복구하기엔 복구 절차서가 너무 오랜 세월이 지나 버렸다. 거기에 조직의 인원 또한 수시로 변경됨에 따라 이러한 상황을 인지하지 못하는 경우가 허다하다. 그 누가 자신이 운영 부서로 부임되고 나서 재해가 발생하게 될 거라고 상상이나 하겠는가?
둘째, 변경 관리가 쉽지 않다. 앞서 언급된 오래된 복구절차서와 일맥 상통하는 내용이다. IT 인프라가 최초 구축될 당시의 형태를 수년간 유지하면서 운영되는 조직은 없을 것이다. 자원들의 추가, 폐기, 변경, 업데이트 등 거의 매일같이 발생하는 변경사항은 재해복구 센터에도 동일하게 적용되어야 한다. 그러나 시간이 지날수록 운영센터와 재해복구센터 간 환경 차이는 점점 커져가고 복구를 해야 할 시점에서 실시간으로 복제된 데이터가 아주 오래된 애플리케이션에서 인식을 못 하는 사태가 부지기수로 발생되고 있다.
셋째, 제대로 된 복구 테스트를 하지 못한다. 백업 솔루션을 도입하는 이유가 무엇이냐고 물어보면, 10명 중 9명은 데이터 백업을 위해서 도입한다고 대답한다. 틀린 대답이다. 목적은 복구를 위한 것이고 백업은 이를 위한 과정일 뿐이다. 그런데 이를 공급하는 솔루션 벤더들은 대부분 백업에 대해서 이야기하지 복구에 대해서는 거의 언급하지 않는다. 또한 이러한 솔루션들은 백업에 대해서는 자동으로 스케줄을 걸어놓고 수행을 하는데 반해 복구는 100% 수작업으로 진행한다. 이러한 불편함 때문에 복구를 위한 테스트를 제대로 하기 쉽지 않다. 사실 복구 테스트를 한 달에 한 번 주기적으로 제대로 진행을 한다면 첫째와 둘째에서 언급되었던 복구 리스크를 쉽게 찾아내고 보완할 수 있다. 하지만 이에 대한 테스트를 제대로 진행하지 못하는 관계로 재해복구는 무용지물이 되어 버리고 큰 IT 재해 때만 반짝 관심을 보였다가 사그라지는 현상이 계속 반복되고 있다.
이제 백업과 복제에만 기울여왔던 관심을 ‘복구’로 돌려야 한다. 제대로 된 복구를 위해서 어떻게 해야 할지에 대한 프로세스를 정립하고 이를 실천해야 한다. 우리의 모든 일상생활이 디지털로 전환되어가고 있기 때문이다. 데이터 센터의 단순 화재가 열흘 넘는 복구 지연으로 수많은 영세 자영업자에게 매출 중단이라는 눈물을 안겨서야 되겠는가? IT 운영의 가장 기본인 백업과 복구가 되지 않는 것으로 인해 IT 강국에 오점을 남기지는 말아야 하겠다.
해당 칼럼은 아래 URL (디지털데일리 전문가 기고) 으로도 확인 가능합니다.
1부, 취약점 드러낸 IT 재해복구 진단
http://www.ddaily.co.kr/news/article.html?no=175882
2부, 100% 복구 가능한 재해복구 시스템을 어떻게 갖출 것인가
http://www.ddaily.co.kr/news/article.html?no=175587