물리적 환경, 가상환경 및 혼합환경의 Windows 와 Linux 플랫폼에 대한
미션 / 비지니스크리티컬한 애플리케이션의 고가용 및 재해복구를 지원 합니다.
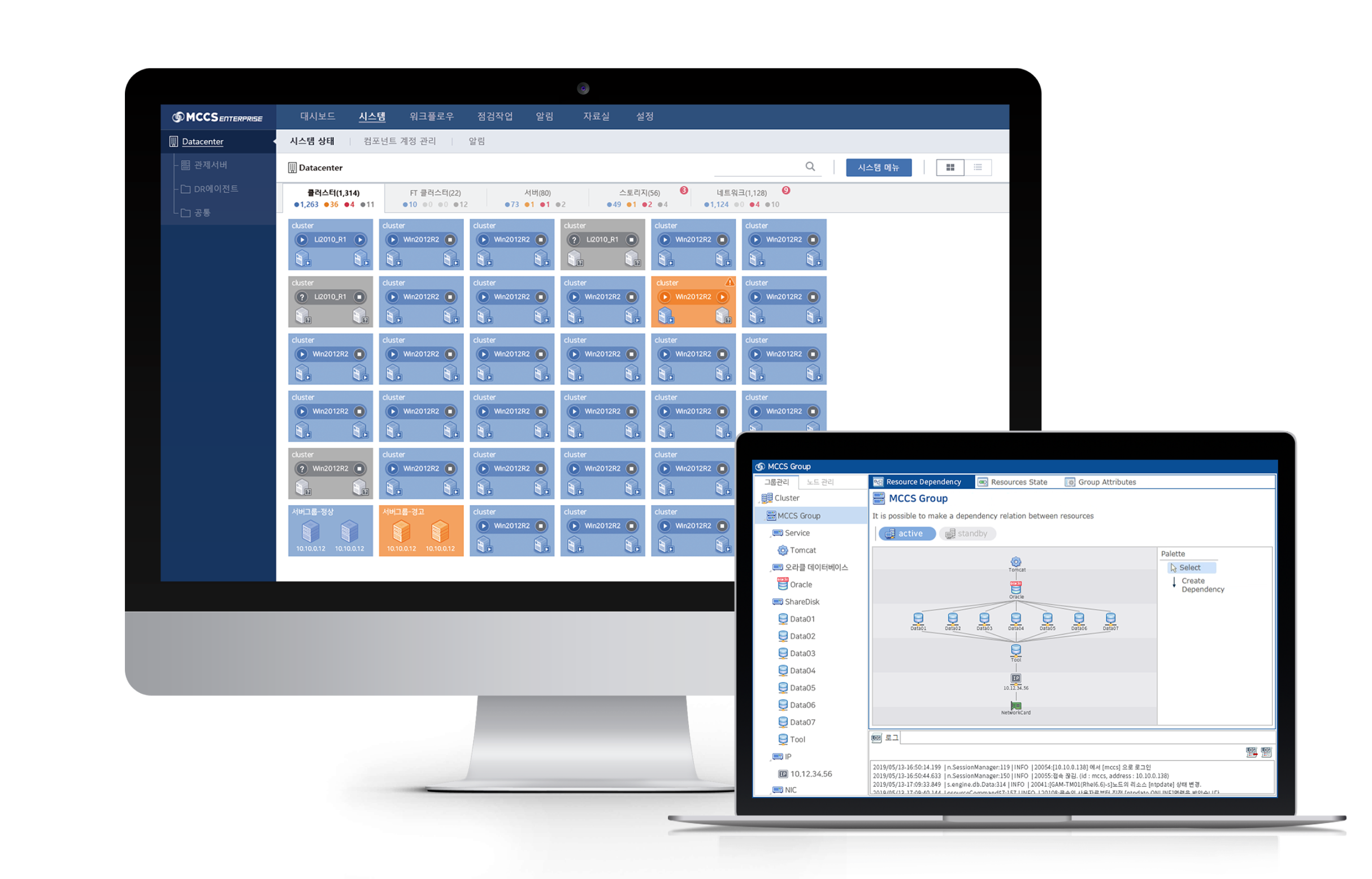
솔루션
MCCS
High Availability
MCCS
MCCS는 서버, 애플리케이션 서비스, 네트워크, 스토리지 뿐만 아니라
시스템 리소스와 애플리케이션 리소스 문제로 인한 장애에 대해서
서비스 연속성을 보장하고 가용성을 극대화 할 수 있는 솔루션 입니다.
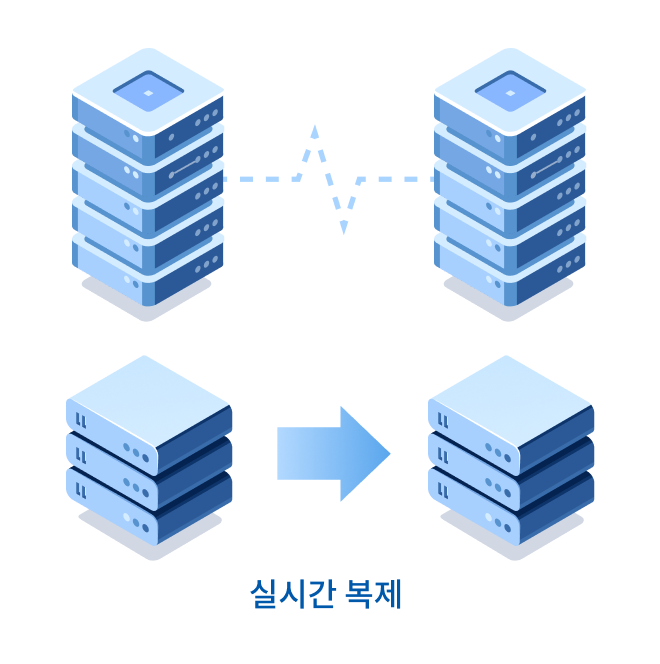
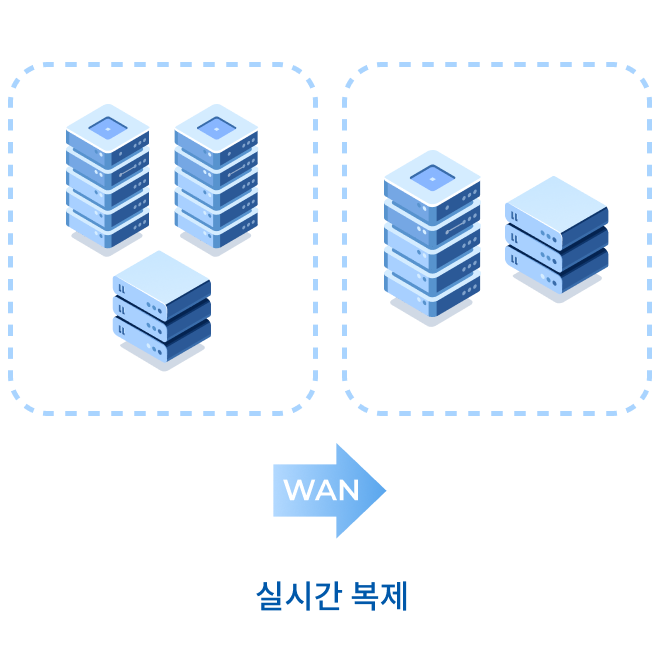
MCCS는 자동 장애 처리 및 실시간 데이터 복제를 통해서 미션
크리티컬한 애플리케이션을 24 x 7 / 365일 운영 할 수 있도록 합니다.