
장애 감지와 자동 페일오버
미션 크리티컬(Mission-Critical)한 업무 환경에 자연재해, 시스템 오류, 운영자 실수 등으로 인한 서비스 중단은 막대한 비용 손실을 발생시키고
기업의 사회적 이미지, 경제적 가치에도 영향을 미칩니다.
장애는 크게 서버, 응용프로그램, 네트워크, 디스크 장애로 나뉘며 아래와 같은 상황이 발생하면 장애로 판단합니다.
-서버 장애 : 서버가 셧다운 된 경우
-응용 프로그램 장애 : 응용 프로그램을 모니터링했을 때 응답이 없는 경우
-네트워크 장애 : 네트워크 통신이 단절된 경우
-디스크 장애 : 운영 노드 디스크에 읽기/쓰기가 불가능한 경우
고가용성이란 서버, 네트워크, 응용프로그램 등의 정보 시스템 서비스를 중단 없이 수행할 수 있는 능력을 말합니다.
운영 노드에서 장애가 감지되면, 대기 노드로 자동 페일 오버하여 서비스를 지속할 수 있게 합니다.
자동 페일오버(Failover)는 다운타임을 최소화하고 장애 발생 시 동일 수준의 서비스를 자동 복구함으로써 서비스 가용성을 극대화시켜 인프라 안정성을 제공합니다.
즉, 시스템에 장애가 오면 미리 준비했던 다른 시스템으로 대체해서 운영을 하는 것 입니다.
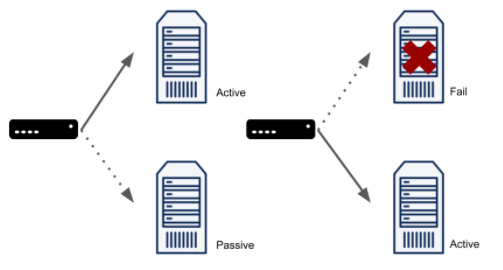
서비스 레벨의 장애 감지와 자동화된 페일오버를 제공하는 MCCS
맨텍의 고가용 솔루션 MCCS(Mantech Continuous Cluster Server)는 서버, 애플리케이션 서비스, 네트워크, 스토리지 뿐만 아니라
시스템 리소스와 애플리케이션 리소스 문제로 인한 장애에 대해서 서비스 연속성을 보장하고 가용성을 극대화 할 수 있는 솔루션으로,
자동 장애 처리 및 실시간 데이터 복제를 통해서 미션 크리티컬한 애플리케이션의 비즈니스 연속성을 보장합니다.
MCCS는 하드웨어의 장애뿐만 아니라 서비스 제공에 필요한 자원들(예를 들면 네트워크 접속, 응용프로그램 구동, 플랫폼 상태, 디스크 접속 등)에 대해서
정상적인 상태인지를 항상 감시하고 관리합니다. 따라서 해당 자원들에 대해 장애 상태가 감지되어 정상적인 서비스 제공이 불가능한 경우에는
유연한 복구 정책에 따라 자동적으로 서비스를 재기동 시키거나 다른 가용 서버로 페일오버 시키게 됩니다.
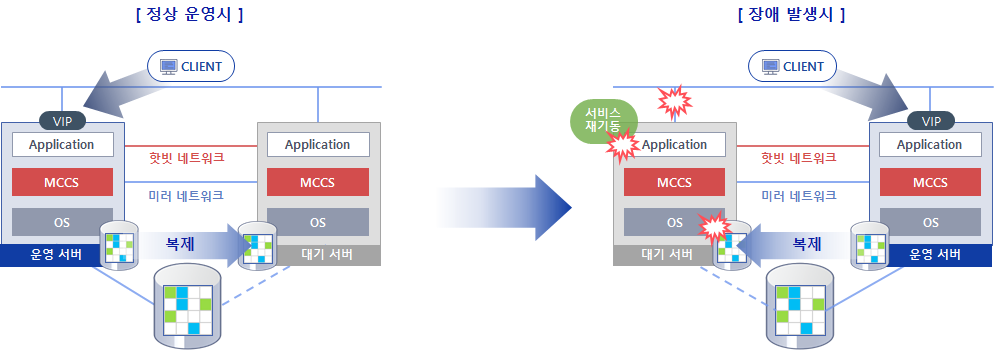
-감시 대상 자원의 장애 발생 시 대기 서버로 자동 페일오버
-서비스 레벨 장애의 경우 사용자 지정 횟수만큼 로컬 재 기동 수행
-기존 운영 서버 복구 시 자동으로 대기 서버로 전환
-운영/대기 서버 전환 시 자동으로 데이터 복제 방향 전환
-장애발생서버 복구 후 GUI내에서 손쉬운 수동 페일오버 가능
또한 MCCS는 이중화 대상을 그룹별로 관리하여 자원 활용률 및 운영 효율성을 확보할 수 있습니다.
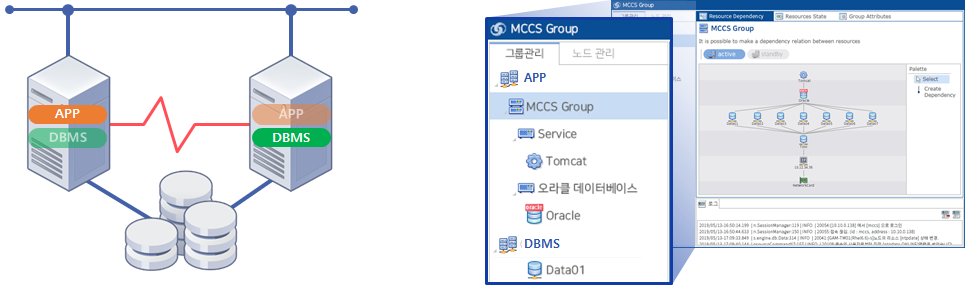
-이중화 대상 업무와 각 시스템 별 그룹 생성 가능
-생성된 그룹별 제어 가능
-그룹별 페일오버를 통한 다운타임 최소화
-두 개 이상 업무 상화 대기 (Active-Active) 형태로 구성 가능
비즈니스의 연속성을 위한 MCCS 솔루션 문의 및 구축 상담은 info@mantech.co.kr 로 연락 주시기 바랍니다.